




Der Digitale Zwilling ist ein Knowledge (Sub-) Graph
Jochen Hechler von der Continental AG und Tim Rathgeber von CONWEAVER präsentierten auf dem Symposium eine Graphen-basierte Lösung für die Continental AG in Bezug auf Supply Chain und Data Governance ("Automated Enterprise Knowledge Graph for Corporate Data Governance", siehe [1]). Bei CONWWEAVER sind weitere Lösungen entstanden, auch komplett vernetzte Schichten wie im Fall von Daimler, Lösungen für Volkswagen, General Motors, Bosch, Hella. Einige dieser Lösungen haben weit mehr als 10.000 aktive Nutzer. Markus Krastel von em engineering und Olaf Kramer von Bosch (Holistic PLM in the age of Systems Engineering and Digital Transformation at BOSCH, siehe[2]) skizzieren eine ganzheitliche PLM-Lösung, die über die etablierte Graphen-basierte PLM-Lösung für das Engineering hinausgeht. Allerdings sieht Gartner Knowledge Graphen noch als eine aufstrebende Technologie, die kurz vor dem Durchbruch steht. Den Stand von Knowledge Graphen haben auch Jörg Werner von Merck, Felix Lösch von Bosch und Vinod Surendran von Deloitte im smart data blog diskutiert. Sie erkennen an, dass der Knowledge Graph-Markt noch in den Kinderschuhen steckt. Vinod Surendran sagt voraus, dass sich dies innerhalb der nächsten zwei Jahre drastisch ändern wird. Also, seien Sie vorbereitet!
Der Hauptgrund, den sie sehen, ist zweierlei: Die Technologie selbst ist ausgereift und die Herausforderungen, denen sich die Kunden gegenübersehen, verlangen nach einem solchen ganzheitlichen Ansatz. Im Falle des Produktlebenszyklus werden Knowledge Graphen einen großen Einfluss auf die Bereitstellung von Daten für die Geschäftsrollen entlang des Prozesses haben und leichtgewichtige Graphen-basierte Lösungen werden auf die Anforderungen des Informationsbedarfs dieser Rollen zugeschnitten sein. Damit werden Knowledge Graph-basierte Lösungen zu den eigentlichen PLM-Werkzeugen. Autorenwerkzeuge haben sich nie und werden sich nie zu echten PLM-Werkzeugen entwickeln. Dafür sind sie nicht gedacht, egal wie das Marketing sie bezeichnet. Im Gegensatz dazu werden Knowledge Graph-Technologien nur dann einen Durchbruch erleben, wenn die Business-Orientierung die technologische Entwicklung vorantreibt, d.h. Knowledge Graph-basierte Lösungen müssen dem Business-Anwender unmittelbar einen Mehrwert bieten.
Der Lebenszyklus von Business Objekten
Fachanwender wie Ingenieure, Vertriebsmitarbeiter, Einkäufer und andere sind naturgemäß mit betriebswirtschaftlichen Aufgabenstellungen befasst. In Bezug auf IT-Konzepte führt dies zur Verwaltung von Stammdaten über Produkte, Dienstleistungen, Anlagen, Kunden usw. entlang der Wertschöpfungskette. In dedizierten Prozessen werden die entsprechenden Geschäftsobjekte entlang verschiedener Prozessphasen angelegt, geändert und stillgelegt. Dies geschieht mit Hilfe spezialisierter Autorensysteme. In der Fertigung unterscheidet der Produktlebenszyklus Phasen wie "Definieren", "Entwerfen", "Validieren", "Planen", "Bauen", "Prüfen", "Betreiben", "Stilllegen". Dementsprechend erstellt der nachgelagerte Prozess eine Dokumentation in Form von z. B. Anforderungsdokumenten, "as-designed", "as-built", "as-delivered"-Stücklisten usw. Die Dokumentation ist hochgradig verflochten, da das im Fokus stehende Objekt durch die verschiedenen Phasen hindurch in Erscheinung tritt. Diese Verflechtungen, ja sogar Abhängigkeiten, werden zu einer Herausforderung, da durch die Arbeitsteilung verschiedene Organisationseinheiten unterschiedliche Autorenwerkzeuge verwenden, so dass die Anschlussfähigkeit verloren geht und Komplexität entsteht. Aus diesem Grund sind Konzepte wie der Digital Thread und der Digital Twin entstanden. Sie verkörpern die Notwendigkeit der Konnektivität und damit die Bereitstellung von Geschäftskontext in einem nachgelagerten Prozess, der nur lose datentechnisch gekoppelt ist. Der nachgelagerte Prozess enthält jedoch eine ganze Reihe von Rückkopplungsschleifen, die die Komplexität noch erhöhen. Dieser Trend wird sich mit kommenden servicebasierten Architekturen und neuen Geschäftsmodellen noch verstärken.
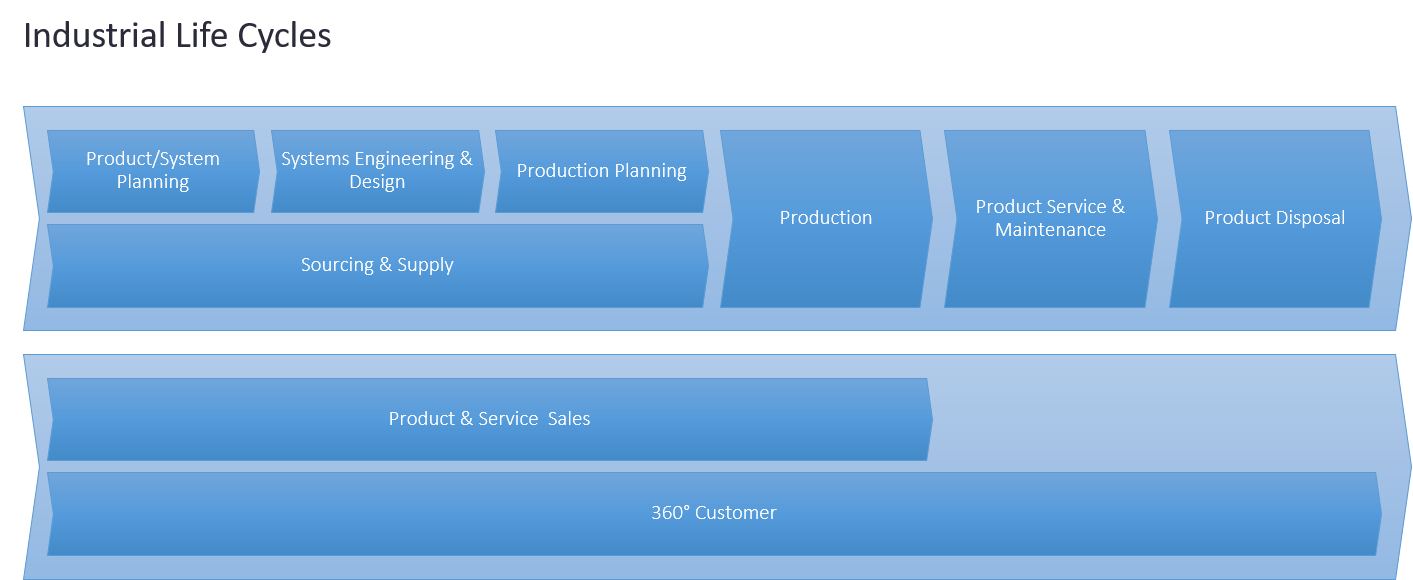
Feedback-to-Design-Schleifen und der Digitale Zwilling
Historisch gesehen wurde das Konzept des Digitalen Zwillings aus der Perspektive eines physischen Artefakts diskutiert, dessen Modell fehlt. Physische Produkte, Komponenten oder Anlagen würden sich eine Verbindung zu ihrem Modell wünschen. Dies könnte besonders hilfreich sein, um z.B. die Nachverfolgung, die Auswirkungen von Änderungen und viele andere Aufgaben entlang des Prozesses zu unterstützen. Dies ist jedoch eine retrospektive Sicht auf die Angelegenheit. Wenn wir den Standpunkt des modellbasierten Systems Engineering einnehmen, dann ist das physische Produkt nur eine spätere Instanziierung des digitalen Modells in einem frontgeladenen Produktlebenszyklusprozess. Eine solche prospektive Sichtweise hat einige Vorteile. Beispielsweise haben Karsten Klemm von der Mercedes Benz AG und Theresa Riedelsheimer vom Fraunhofer IPK in einem Forschungsprojekt ("Bridging the Gap", siehe [3]) gezeigt, dass Feedback-to-Design-Schleifen als ganzheitliches Mittel in frühen Phasen helfen, mehr Raum für Energieeffizienzoptimierung in der Produktion zu lassen.
%20K.%20Klemm%20%26%20T.%20Riedelsheimer.png)
Eine zentrale Anforderung, abgeleitet aus ihren Untersuchungen, besagt, dass Engineering-Daten und Produktionsdaten (Stamm- und Schattendaten) verbunden werden müssen, damit diese Methode funktioniert. Dies ist ein Beleg für die Tatsache, dass die meisten Unternehmen in einer existierenden Datenlandschaft arbeiten. Sie konnten zeigen, dass auf der Grundlage ihrer Vorgehensweise, verschiedene Arten von Produktvarianten unter dem Aspekt der Energieeffizienz besser geeignet waren. Sie behaupten sogar, dass Digitale Zwillinge in Zukunft Nachhaltigkeitsbewertungen durchführen können. Dies ist eine bemerkenswerte Aussage, weil sie den Anspruch erhebt, dass ein Digitaler Zwilling ein aktiver Akteur wird und nicht nur ein passiv verwaltetes Informationsobjekt ist. Prof. Riedel des Fraunhofer IAO hat gezeigt, dass durch den Einsatz von Frontloading gleichzeitig ein früherer SOP ermöglicht und der Übergang zwischen Engineering und Produktion geglättet werden kann. Dies ist ein wichtiger Aspekt in Bezug auf die digitale Fertigung, denn wie bereits erwähnt, ist der nachgelagerte Prozess nicht nur ein linearer Prozess, sondern enthält Schleifen. Kürzlich teilte Matthias Ahrens einen Link zu [4], der meine Aufmerksamkeit erregte, in dem Jim Brown von Tech Clarity
zwei primäre Werttreiber hervorhebt: die Rationalisierung des Engineerings und die Schaffung digitaler Kontinuität. Noch wichtiger ist, dass diese Faktoren das Mittel zu erheblichen geschäftlichen Verbesserungen sind. Zu den Vorteilen gehören verbesserte Qualität, höhere Effizienz, kürzere Durchlaufzeiten, verbesserte Innovation und mehr. Konkret zeigt unsere Studie, dass Unternehmen, die einen Digital Thread eingeführt haben, ihre technischen Ressourcen in die Lage versetzen, 10 % mehr wertschöpfende Zeit auf Innovation, Design und Entwicklungsarbeit zu verwenden.
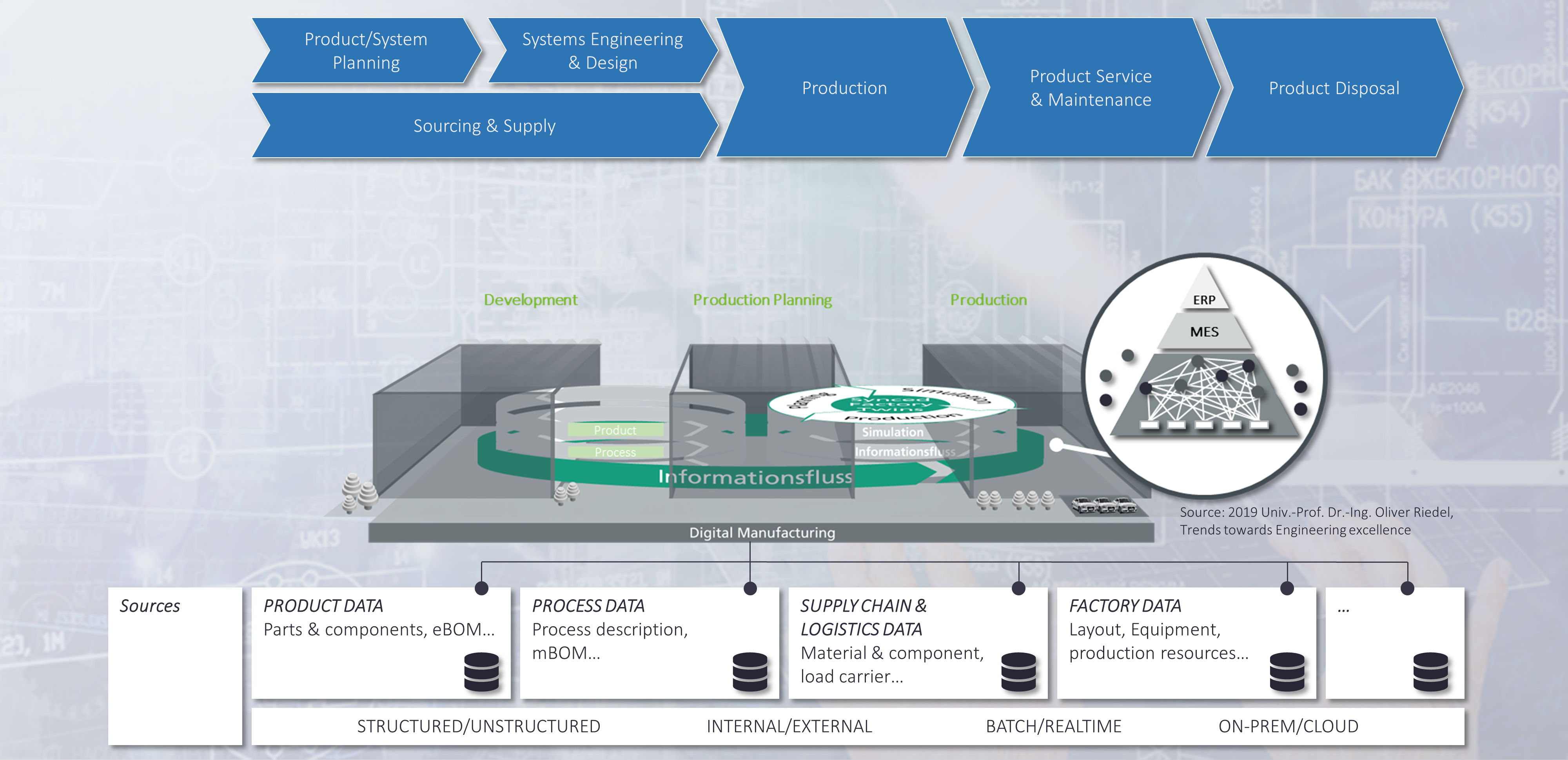
Was ist der Digitale Zwilling?
Für meinen Geschmack sind der Digitale Zwilling und der Digitale Thread noch unscharfe Begriffe. Für meinen Geschmack sind der Digitale Zwilling und der Digitale Faden noch unscharfe Begriffe. Die Vorstellungen darüber, was diese Begriffe bedeuten, sind bei verschiedenen Menschen unterschiedlich. Marcin Humpa von Mahle und Michael Kirsch von em engineering ("Benefits & Challenges of Model-based Engineering & Use of Standards", siehe [5]) unterscheiden drei aufeinander aufbauende Phasen entlang des PLM-Prozesses: Requirements Engineering und MBSE, den Digital Master und den Digitalen Zwilling. In ihrem Modell ist der Digitale Zwilling eng mit der physischen Instanz des im Fokus stehenden Geschäftsobjekts verbunden. Sie argumentieren, dass die dokumentenbasierte Entwicklung zugunsten von modellbasierten Systems Engineering-Methoden überwunden werden muss, bei denen der erste Schritt die Erstellung eines digitalen Masters wäre. Dem kann ich nur zustimmen! Allerdings sind abstrakte Objekte wie Prozesse als eigenständige Geschäftsobjekte von Interesse. Sie haben selbst keine physische Instanz, aber sie durchlaufen einen ähnlichen Lebenszyklus. Sie werden mit Geschäftsprozessmanagement-Tools und Workflow-Management-Systemen verwaltet und sind in vielen Fällen als Kern von Anwendungssystemen eingebettet. Application Lifecycle Management (ALM) ist die dem PLM entsprechende Geschäftskategorie. Getrieben von den Markttrends wachsen PLM und ALM immer enger zusammen. Die Softwareentwicklung hat sich sogar zum wichtigsten Innovationstreiber in der Fertigungswelt entwickelt. Daher ist es sinnvoll, den Digitalen Zwilling aus einer allgemeineren Perspektive zu betrachten.
Ausgehend von der modellbasierten Systementwicklung und unter Berücksichtigung der oben besprochenen Phasen des PLM-Prozesses mit ihren wesentlichen Ergebnissen - den verschiedenen Arten von Dokumentationen, die in unterschiedlichen Autorensystemen gepflegt werden - gibt es diskrete Schritte im Prozess, die von besonderem Interesse sein könnten, beispielsweise zu erreichende Quality Gates. Sie repräsentieren unterschiedliche Reifegrade eines Produkts, einer Anlage, eines Prozesses oder einer Software-Dienstleistung. Je weiter das Geschäftsobjekt entwickelt ist, desto mehr Sichten können die Geschäftsrollen entlang des Prozesses haben. Verschiedene Sichten ermöglichen spezifische Antworten auf geschäftliche Fragen von verschiedenen Beteiligten.
Enterprise Knowledge Graphs, ein natives Mittel zur Repräsentation von Geschäftskontext
Wie beschrieben in meinem Artikel "Woran sollte man denken, wenn man Lebenszyklen/Prozesse verknüpfen möchte" (siehe [6]), sind EKGen ein natives Mittel, um vernetzte Geschäftsdaten zu repräsentieren. Graphenstrukturen im mathematischen Sinne können semantische Kontextinformationen darstellen, indem sie "Knoten" (Objekte) mit "Kanten" (Beziehungen) verbinden. In einem EKG sind die Knoten relevante Geschäftsobjekte, während die Kanten die entsprechenden semantischen Beziehungen darstellen, die sie verbinden. Sie können schnell (inkrementell) aus der existierenden Datenlandschaft automatisiert berechnet werden (siehe [7]) und lassen bestehende Datenarchitekturen und -prozesse unberührt. So können z.B. digitale Datenpakete, wie sie von Ralf Burghoff ("Zwischen 3DEXPERIENCE und 4PEP", siehe [8]) sowie Marcin Humpa und Michael Kirsch in [5] beschrieben werden, leicht der Ausgangspunkt für die automatische Erstellung von EKGen sein. Letztere sind als solche ein sehr pragmatisches Mittel zur Herstellung des Geschäftskontextes, z. B. durch die oben diskutierte Überbrückung der Kluft zwischen dem "digitalen Meister" und dem "digitalen Schatten". EKGen erlauben beliebige Sichten auf Geschäftsobjekte, die durch intelligente Graphen-Traversalen definiert werden - abfragebasiert, regelbasiert, browsend. Sie ermöglichen sogar Einblicke mittels KI-basierter Inferenztechniken und decken so verborgene Korrelationen oder Kausalitäten auf.
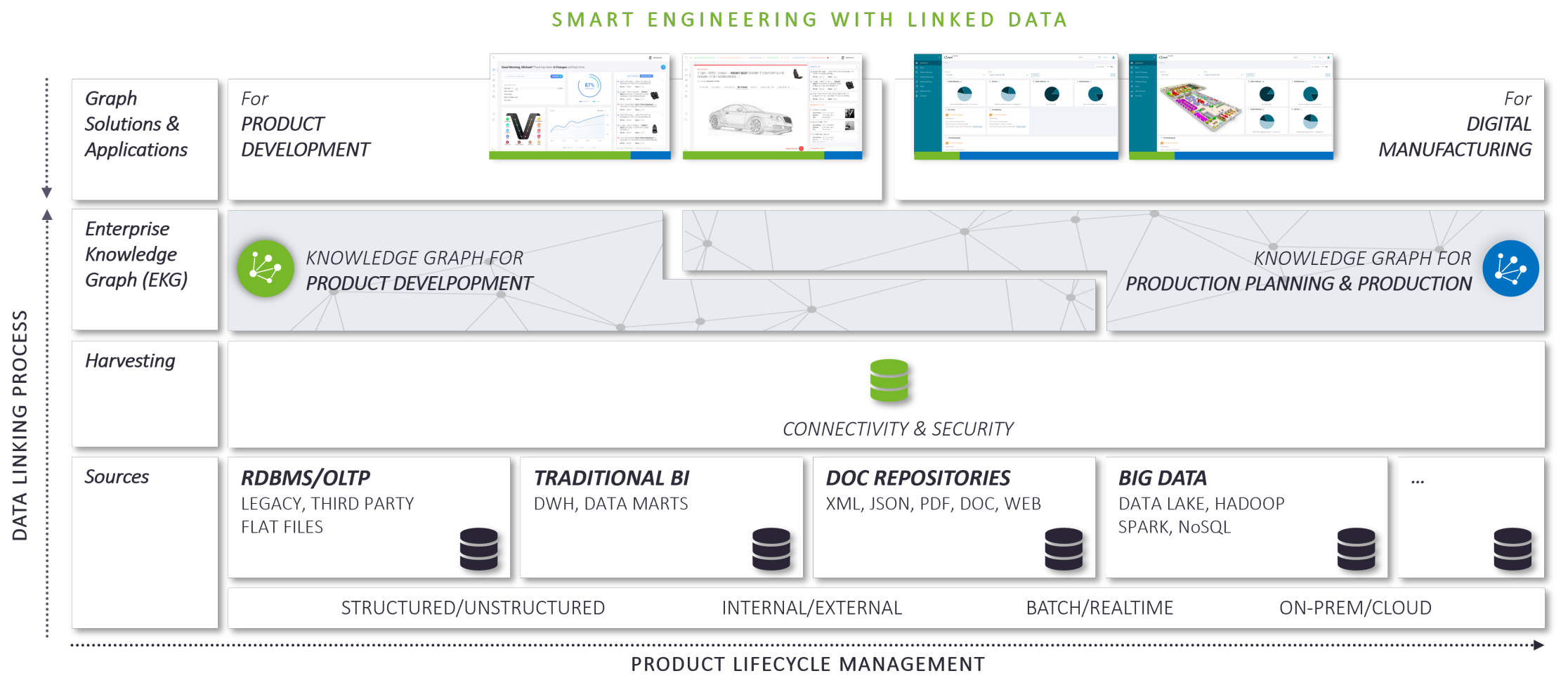
Der Digitale Zwilling umfasst den Geschäftskontext eines Geschäftsobjekts von Anfang bis Ende
Aus der obigen Diskussion ist ein Digitaler Zwilling eine komplexe Entität, die sich mit der Zeit entlang des Produktlebenszyklus entwickelt und sich in physische Instanzen verwandelt, die ausgeliefert werden und Sensordaten produzieren. Ein Digitaler Zwilling stirbt nie, es sei denn, seine Daten werden gelöscht. Daher lassen sich die strukturellen Aspekte des Digitalen Zwillings sehr treffend mit einem EKG abbilden. Ein Digitaler Zwilling umfasst viele weitere nicht-strukturelle Aspekte wie Simulationsprogramme oder digitale Prototypen, die dazu dienen, das Verhalten einer physischen Instanz im Voraus zu studieren. Aus der Sicht des Prozesses sind das jedoch nur Daten, die mit anderen Daten entlang des Prozesses verbunden sind. Wenn wir den gesamten Geschäftskontext eines Produkts, eines Prozesses, einer Anlage von Anfang bis Ende als den Digitalen Zwilling dieses Objekts sehen, dann ist der Digitale Zwilling ein Untergraph eines EKGen. Das heißt, ein Digitaler Zwilling ist ein Graph, dessen Knotenmenge eine Teilmenge der Knotenmenge des EKGen ist und dessen Kantenmenge eine Teilmenge des EKGen ist. Daher können verschiedene Digitale Zwillinge Überschneidungen haben, gemeinsame Geschäftsobjekte und Beziehungen teilen. Ein Digital Thread stellt das Modell eines Digitalen Zwillings dar - seine abstrakte Beschreibung, aus der Instanziierungen abgeleitet werden können. Dies entspricht weitgehend der Definition in Wikipedia [9]. Solche Konzepte erlauben dann die Spezifikation der in ([10], "Rise of the digital twin") von Uwe Uttendorfer von Mercedes Benz AG und Oliver Hornberg der Unity AG erwähnten Beispiele des Digitalen Zwillings mit Hilfe von Subgraphen von EKGen.
- Realisierbare Fahrzeuge: logische Formeln für die Konstruktion einer Instanz des Digitalen Zwillings
- Physische/gebaute Fahrzeuge: Instanzen von Digitalen Zwillingen
- Teile und Komponenten: Instanzen von Digitalen Zwillingen
- Digitale Prototypen: Instanzen von digitalen Zwillingen
- Vom Kunden konfigurierte Fahrzeuge: Instanzen von Digitalen Zwillingen
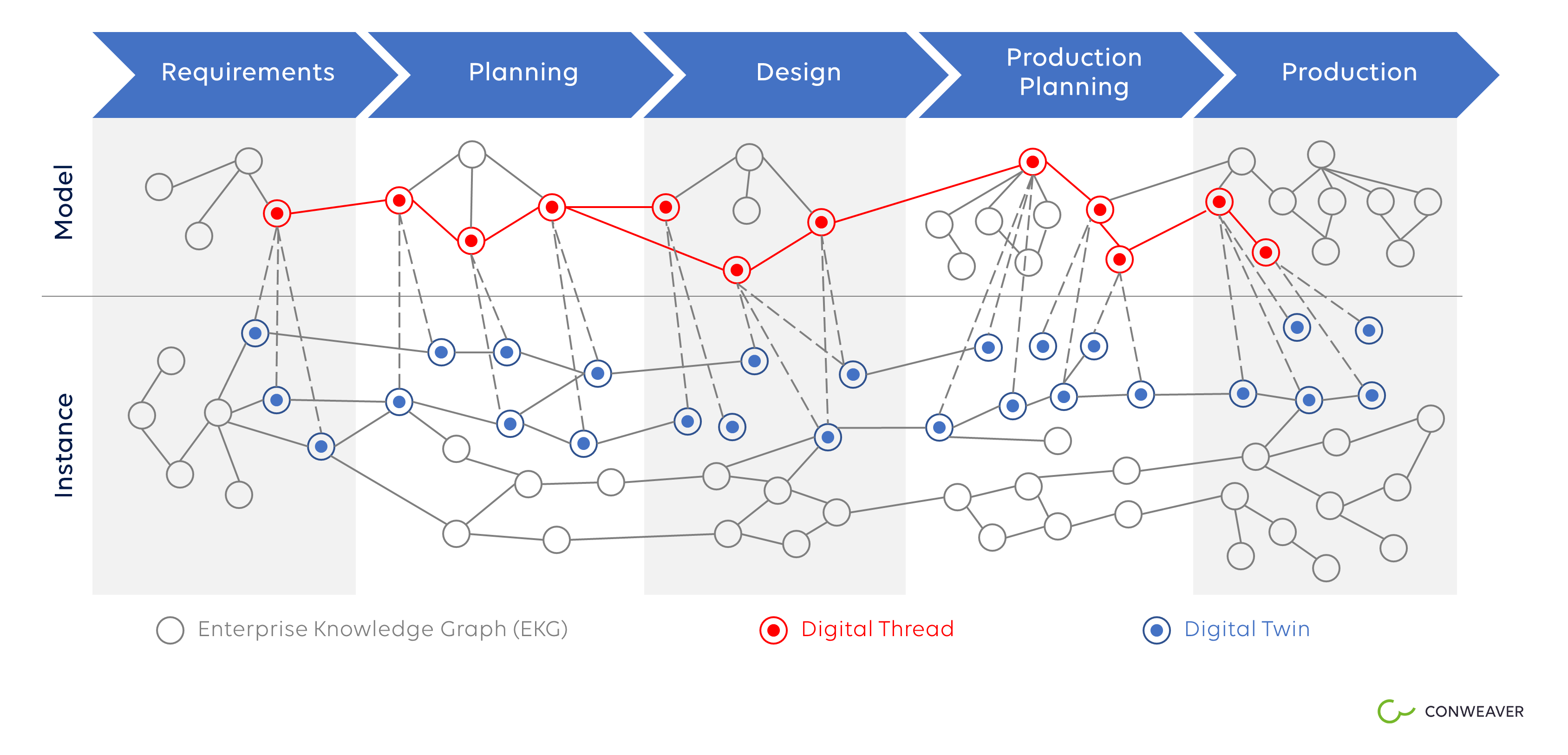
EKGs und Ontologien: Horizontale vs. vertikale Struktur
Weil Standardisierung die Dinge einfacher machen soll, ist die Einführung von Normung seither ein Treiber der technologischen Entwicklung. Geschäftsontologien sind ein Ausdruck dieses Bestrebens. Sie befassen sich mit der Standardisierung von Daten. Geschäftsontologien repräsentieren eher statisches Domänenwissen über Prozesse, Software, Mechanik oder andere Domänen, wie von René Bielert und Tamara Hofman beschrieben ("A cross-disciplinary information model for interdisciplinary collaboration", siehe [11]). Im Gegensatz zu vertikalen Geschäftsontologien stellen EKGen dynamische, horizontale Strukturen dar. Sie sind perfekt geeignet, um relevante Geschäftsobjekte entlang von Prozessen zu verbinden. Auf diese Weise sind sie ein großartiges Werkzeug, das domänenübergreifende (Mechanik, Elektronik, Software), prozessübergreifende und sogar unternehmensübergreifende Transparenz unterstützen kann. Beide Strukturen passen gut zusammen, da es sich um Graphen mit möglichen Schnittmengen handelt. So können Domänenontologien leicht Teil des zugrundeliegenden Datenmodells des EKGen oder Knoten des Graphen selbst werden. Letzteres hängt im Wesentlichen von der Gestaltung des Graphen ab.
EKG-basierte Lösungen
Technische Voraussetzungen
Knowledge Graphen und Digitale Zwillinge ermöglichen die lückenlose Erfassung von Inhalten entlang des Lebenszyklus, indem sie Metadaten aus den Autorensystemen sammeln und diese miteinander verbinden. Aufgrund der schieren Größe der Datenmenge, der Komplexität der Zusammenhänge und der schnellen Verfügbarkeit ist es eine wesentliche Anforderung, dies automatisiert zu erreichen. Eine skalierbare Knowledge Graph-Plattform benötigt daher Low Code-Analysefunktionen, die eine generative Konstruktion und Aktualisierung von Graphen ermöglichen. Mit großer Skalierung meine ich sowohl die Speicherkapazität, mehr als 1.000.000.000 Objekte und eine Vielzahl von Links für eine einzige Lösung, als auch eine große Anzahl von Benutzern, in der Größenordnung von >10.000, die gleichzeitig aktiv an der Lösung arbeiten. Dies garantiert eine schnelle Auslieferung der Lösung und eine hohe Produktivität für den Anwender als Anforderungen an den Kundennutzen. Gleichzeitig ist die Größe ein relevantes Unterscheidungsmerkmal im Vergleich zu Ontologien, die typischerweise in Handarbeit erstellt werden und daher in ihrer Größe begrenzt sind.
Gestaltungsprinzipien für Wissensgraphen
In einer datengetriebenen Wirtschaft sollte es ein Gestaltungsprinzip sein, vorhandene Daten so weit wie möglich zu nutzen, um dem Kunden einen Mehrwert zu bieten und getätigte Investitionen zu steigern. Ein weiteres Designprinzip sollte sein, den Kunden so wenig wie möglich mit unnötigen Aufgaben zu belasten. Aus diesem Grund raten wir von CONWEAVER unseren Kunden, ein inkrementelles Bottom-up-Design des Knowledge Graphen anstelle eines Top-down-Ansatzes zu verfolgen. Bottom-up bedeutet, die IT-Landschaft so zu nehmen, wie sie ist, statt einen vermeintlich sauberen Überbau (Datenmodell/Ontologie) aufzusetzen, der von einem Standardisierungsgedanken geleitet ist. Drei Gründe dafür: 1. Der Bottom-up-Ansatz liefert sehr schnell Nutzen und lässt etablierte Prozesse intakt. 2. In unserem Ansatz kommt die Standardisierung nicht durch das Aufzwingen von Struktur, sondern durch Abstraktion von der konkreten Datenlandschaft und den Prozessen. Wir sehen IT-Anbieter, die eine OSLC-basierte Verknüpfung des Lebenszyklus fordern. Dies ist jedoch nur eine weitere Möglichkeit, die Kunden mit einer Top-down-Standardisierung zu belasten. Sie drängt sie dazu, ihre Daten richtig zu beschriften, um es den Anbietern von IT-Lösungen leicht zu machen, diese Daten zu sammeln und abzubilden. Wir sind der Meinung, dass es stattdessen die Aufgabe der Softwareanbieter sein sollte, geeignete Analysetools bereitzustellen. (Ich liebe PTC's sehr analytischen Ansatz zur Verknüpfung des Produktlebenszyklus, aber pdm + OSCL könnte eine problematische Antwort auf die Herausforderung sein, siehe „Woran sollte man denken, wenn man Lebenszyklen/Prozesse verknüpfen möchte“) 3. Veränderungen der Landschaft können leicht unter dem "Dach" des Knowledge Graphen vorgenommen werden, sobald dieser etabliert ist. Dies bezieht sich auf die Tatsache, dass Datenmigrationsprozesse stark von einer Abstraktionsschicht profitieren können, wie sie durch einen EKG dargestellt wird.
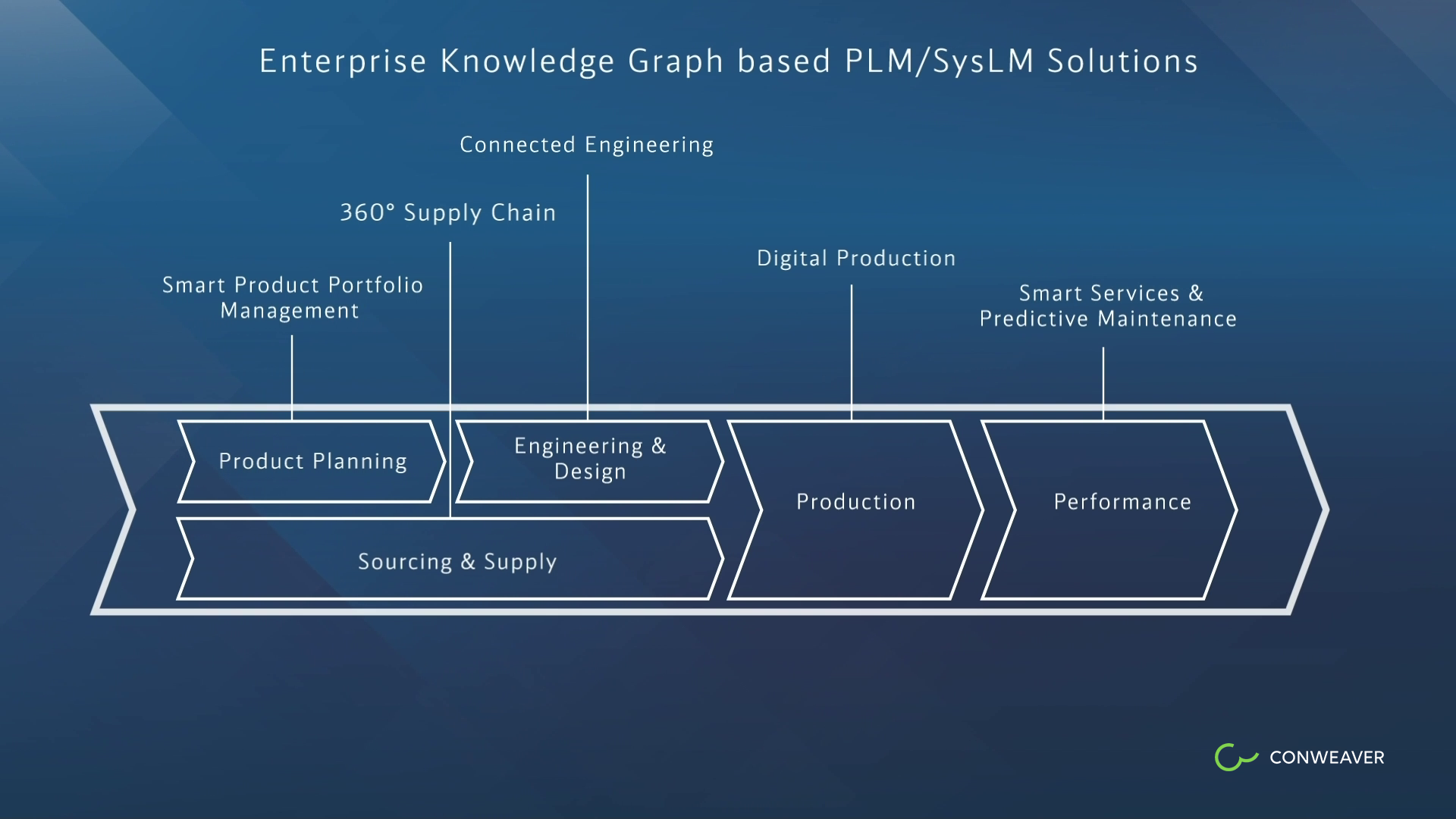
Maßgeschneiderte Lösungen über den gesamten Lebenszyklus
Ein weiterer Vorteil des inkrementellen Bottom-up-Ansatzes ist, dass spezifische Lösungen für bestimmte Rollen im Voraus entworfen werden können, was das Hinzufügen weiterer Lösungen, die denselben EKG teilen oder erweitern, nicht ausschließt, sondern eher ermutigt. Diese reichen von der Produktportfolio-Planung und Systems Engineering-Aufgaben wie Change Impact-Analyse, Root Cause-Analyse, Projektstatusanalyse und Wiederverwendung von Komponenten bis hin zu digitaler Produktion, Smart Services und 360 Grad-Lösungen für die Lieferkette. In unserem Video mit der Continental AG beschreiben wir eine 360-Grad-Supply-Chain-Lösung (siehe [1]), und im Fall von Bosch haben wir eine Enterprise-PLM-Lösung entwickelt, die seit 2014 mit weit über 10.000 Anwendern produktiv läuft. Für Daimler haben wir einen Linked Data-Layer bereitgestellt, um darauf zahlreiche graphbasierte Lösungen zu unterstützen, und dasselbe gilt für andere Kunden.
EKGs und Analytik sind siamesische Zwillinge
Wenn Sie skalierbare, EKG-basierte Lösungen wie oben skizziert anbieten wollen, dann sind stark konfigurierbare Analytik und EKGen ihrerseits siamesische Zwillinge. Dies ergibt sich aus der Tatsache, dass die Daten, aus denen das EKG berechnet wird, in großen Mengen vorliegen, heterogen strukturiert und über die verschiedenen Autorensysteme hinweg inkonsistent sind. Zusammen mit Methoden des maschinellen Lernens bilden EKGen die Bausteine für jede Art von (vorausschauender) Datenauswertung, denn sie bringen Analytik und Struktur zur Synthese und erlauben tiefe Einblicke in die Mechanik des Geschehens. Ein wesentlicher Erfolgsfaktor sind daher die technischen Fähigkeiten der Analytics-Plattform, die für die Berechnung des Graphen eingesetzt wird, in Kombination mit einem erfahrenen Team von Datenanalysten und Knowledge Graph Solution Designern. In den meisten Fällen bieten Lösungsanbieter eine Graphdatenbank an, in der sie Graphen speichern und pflegen können. Der Großteil der Arbeit ist jedoch mit komplizierten Datenaufbereitungsprozeduren verbunden, um zunächst solide und konsistente Daten zu erhalten. Knowledge Graph-Plattformen, die hier eine Schwäche aufweisen, versprechen also viel mühsame Handarbeit bei der Pflege und Anpassung der Lösungen. Rein editierungsbasierte Knowledge Graph-Plattformen sind daher nur begrenzt einsetzbar.
Für weitere Einblicke siehe auch meine anderen Graphen-bezogenen LinkedIn-Artikel
- Woran sollte man denken, wenn man Lebenszyklen/Prozesse verknüpfen möchte
- Neue OEM Geschäftsmodelle stellen die Produktentwicklung auf den Kopf
- Betriebssysteme werden Systems engineering stärken
- Gartner Emerging Technologies: Knowledge graphen werden zur zentralen Komponente des Data Fabric
- Führt konzeptionelle Unschärfe zu einer Suche nach einem neuen Label für PLM
- Linked Data Connectivity – Graphen sind die "Crux of the Biscuit"
Header Bild aus © mammadzada.rashad@gm / adobestock 310074704



