




Graph Mesh und Domänen-Knowledge-Graphen
Zwei Jahrzehnte Knowledge Graph Engineering
Unsere Erfahrung mit Knowledge Graphen reicht bis in die frühen 2000er Jahre zurück. Zu dieser Zeit wurden die meisten Knowledge Graphen manuell modelliert und gepflegt, waren oft begrenzt in ihrem Umfang und schwierig zu warten. CONWEAVER gehört zu den Pionieren, die Knowledge Graphen automatisch aus heterogenen Datenquellen verknüpften und den Fokus von manuell aufgesetzten Strukturen auf die maschinengestützte Graph-Konstruktion verlagerten.
Mittlerweile haben sowohl das Datenvolumen als auch die Granularität der Modelle erheblich zugenommen. Graphen entwickelten sich von isolierten Datensätzen zu unternehmensweiten Repräsentationen, die alle Bereiche von Forschung und Entwicklung (F&E), Produktion, Lieferketten und Vertrieb umfassen. Voraussetzung dafür waren nicht nur Fortschritte in der Software- und Graphentechnologie, sondern auch eine grundlegende Änderung in der Art und Weise, wie Knowledge Graphen modelliert, verwaltet und weiterentwickelt werden.
Zwei fundamentale Paradigmen: Data Driven vs. Business Driven
Es existieren zwei grundlegende Ansätze zur Modellierung von Knowledge Graphen:
In einem datengetriebenen Ansatz werden zuerst die verfügbaren Datenquellen analysiert. Die Struktur des Knowledge Graphen wird aus Schemata, Datenmustern und Beziehungen abgeleitet, die in operativen Systemen gefunden werden.
- Stärken: Hohe Treue zu realen Daten, schnelles Onboarding großer Datensätze, hohe Rückverfolgbarkeit und Data Lineage.
- Einschränkungen: Resultierende Graphen sind oft für einen einzelnen Anwendungsfall optimiert, es gibt nur begrenzte Wiederverwendbarkeit über Domänen hinweg, die Geschäftssemantik bleibt unter Umständen implizit oder fragmentiert.
In einem business-getriebenen Ansatz wird der Knowledge Graph Top-Down entworfen. Geschäftsprozesse und Domänenkonzepte werden in Interviews und Workshops erfasst und bilden ein konzeptionelles Modell, dem die Daten anschließend zugeordnet werden.
- Stärken: Klare Geschäftssemantik, Abstimmung mit Prozessen und der organisatorischen Sprache.
- Einschränkungen: Hoher anfänglicher Modellierungsaufwand, Risiko überdimensionierter Modelle, in der "Green-Field"-Modellierung sind die geschäftliche Anforderungen oft noch unbekannt.
In der Praxis sind wir auf zahlreiche gescheiterte Unternehmensinitiativen gestoßen, bei denen große, modellgetriebene Graphen ohne ausreichende Basis in realen Daten entworfen wurden. Diese Projekte scheitern oft, bevor der erste produktive Datensatz integriert ist.
Der notwendige Hybrid aus Daten- und Business-Ontologien
Rein datengetriebene oder rein modellgetriebene Ansätze skalieren isoliert sehr selten. In der Realität ist ein hybrider Ansatz erforderlich. Bei CONWEAVER leiten wir Modelle aus Daten ab und richten sie kontinuierlich an den Stakeholdern aus. Dies führt zu einem zweischichtigen Modellierungsansatz:
- Daten-Ontologien, die Quellsysteme, Schemata und die technische Herkunft repräsentieren.
- Business-Ontologien, die Domänenkonzepte, Prozesse und die geschäftliche Bedeutung repräsentieren.
Die Daten-Ontologie sichert die Rückverfolgbarkeit zu den ursprünglichen Systemen, die Business-Ontologie bietet semantischen Kontext und domänenübergreifende Bedeutung.
Beispiel: Das Geschäftskonzept „Part”
Ein Geschäftskonzept wie „Part“ kann mit mehreren Datenobjekten verknüpft sein:
- SAP Materialstamm-Datensätze
- Siemens Teamcenter TC_Item
- Bedarfs- oder Planungssystem-Entitäten
Abhängig von der Phase des Produktlebenszyklus unterhält das Geschäftsobjekt unterschiedliche Beziehungen zu diesen Datenobjekten. Im Laufe der Zeit wachsen diese Verknüpfungen und ermöglichen daraus abgeleitete Beziehungen zu Lieferanten, Kunden und anderen Geschäftseinheiten.
Herausforderungen der Skalierung: von der Technik zur Organisation
Wachsen Knowledge Graphen in Größe und Umfang, entstehen neue Herausforderungen, die selten rein technischer Natur sind. Der dominante Engpass ist organisatorisch: Zentrale Ontologie-Teams werden überlastet, Modellierungs- und Governance-Aufwände wachsen superlinear mit der Anzahl der Domänen und domänenübergreifende Abstimmungen verlangsamen die Innovationen.
Wir beobachten immer wieder, dass Teams, die tief mit einer spezifischen Domäne vertraut sind, wesentlich mehr Koordination benötigen, um ihr Modell in neue Domänen zu erweitern, als neu gebildete Domänenteams, die bereits über die relevante Expertise verfügen.
Diese Erkenntnis verändert grundlegend, wie Knowledge Graphen organisiert und verwaltet werden sollten.
Unser Ansatz: Domänen Knowledge Graphen und Graph-Mesh
Um diesen Herausforderungen zu begegnen, setzen wir bei CONWEAVER auf den Graph-Mesh-Ansatz: Jede Domäne besitzt und entwickelt ihren eigenen Domänen-Knowledge-Graphen, Teams arbeiten weitgehend unabhängig und es werden nur die Schnittstellen zwischen Domänen verhandelt. Diese werden als Datenverträge definiert.
Die lose Kopplung zwischen den Domänen ermöglicht es den Teams, lokal innovativ zu sein und gleichzeitig auf Unternehmensebene interoperabel zu bleiben.
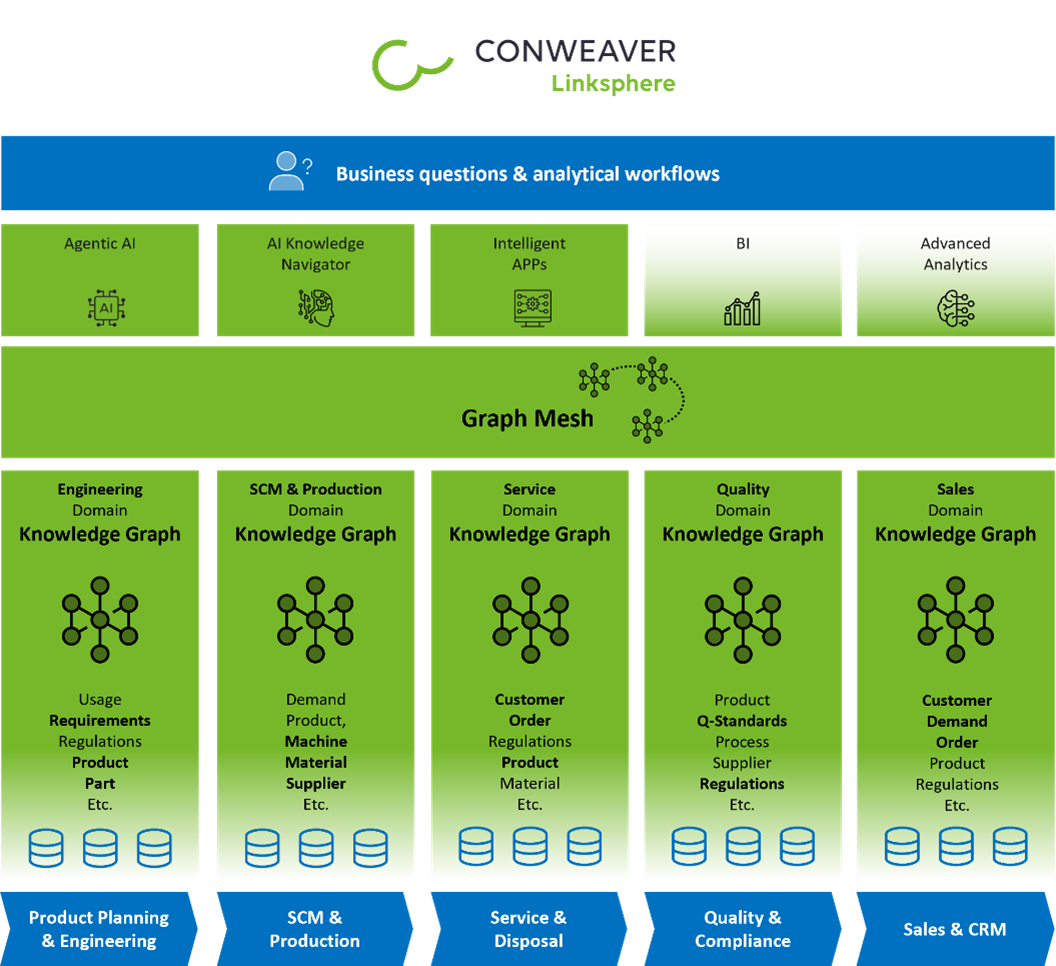
Bidirektionale Indizierung und domainübergreifende Performance
Um funktionsübergreifende Anwendungsfälle zu unterstützen, werden lose gekoppelte Domänenendpunkte innerhalb des Graph Mesh durch explizite, materialisierte domänenübergreifende Beziehungen miteinander verbunden. Diese Beziehungen sind indiziert und in ihrer Traversierungssemantik bidirektional, sodass die Navigation von beiden Seiten einer Domänengrenze aus möglich ist.
Dies ermöglicht eine leistungsstarke domänenübergreifende Traversierung, ohne dass man sich auf die Ausführung von Verbundabfragen zur Laufzeit verlassen muss. Im Gegensatz zu klassischen Verbundansätzen für Wissensgraphen verhält sich ein Graph Mesh wie ein einziger, kohärenter Graph:
- Keine Verbundabfragen zur Abfragezeit
- Keine Laufzeit-Abfragebarrieren zwischen Domänen
- Vorhersagbare domänenübergreifende Traversierungsleistung
- Transparente, bidirektionale Navigation über Domänen hinweg
Im Linksphere Graph Mesh werden domänenübergreifende Abfragen so ausgeführt und funktionieren so, als würden sie auf einem großen Graphen operieren, während Domänenmodelle und Eigentumsverhältnisse entkoppelt bleiben.
Graph Mesh vs. föderierte Knowledge Graphen
Viele Knowledge-Graph-Initiativen in Unternehmen basieren auf föderierten Abfrageansätzen. In diesen Architekturen bleiben mehrere Graphen oder Datenspeicher isoliert, und domänenübergreifende Fragen werden zum Zeitpunkt der Abfrage durch die Verteilung von Unterabfragen und die Aggregation der Ergebnisse gelöst. Dieser Ansatz scheint zwar aus Integrationssicht attraktiv, bringt jedoch strukturelle Einschränkungen mit sich.
- Laufzeitkopplung: Die Ausführung von Abfragen hängt von der Verfügbarkeit und Leistung aller beteiligten Systeme ab.
- Unvorhersehbare Leistung: Die Latenz summiert sich über die Domänen hinweg, was die Operationalisierung funktionsübergreifender Abfragen erschwert.
- Begrenzte domänenübergreifende Schlussfolgerungen: Schlussfolgerungen über Systemgrenzen hinweg sind zum Zeitpunkt der Abfrage eingeschränkt oder nicht möglich.
- Implizite Abhängigkeitsanfälligkeit: Änderungen an Daten, Semantik oder Schemata einer Domäne können sich auf domänenübergreifende Abfragen auswirken, aber diese Abhängigkeiten bleiben implizit und werden erst zur Laufzeit erkannt.
Über Leistung und Verfügbarkeit hinaus stehen föderierte Ansätze vor einer grundlegenderen Herausforderung – der expliziten Verwaltung von Systemgrenzen und semantischen Verknüpfungen:
- Systemübergreifende Beziehungen müssen dynamisch berechnet werden, anstatt explizit modelliert zu werden.
- Semantische Diskrepanzen zwischen Systemen (z. B. eBOM- vs. mBOM-Strukturen) können zum Zeitpunkt der Abfrage nicht zuverlässig aufgelöst werden.
- „Intelligente” systemübergreifende Verknüpfungen erfordern Domänenwissen, das während der Ausführung der Abfrage nicht verfügbar ist.
- Defekte oder hängende Referenzen können nicht systematisch erkannt oder verfolgt werden – Systeme können auf Entitäten verweisen, die nicht mehr existieren oder nie semantisch abgeglichen wurden.
Infolgedessen behandeln föderierte Modelle domänenübergreifende Verbindungen eher als Ausführungsproblem denn als Modellierungsproblem.
Im Gegensatz dazu stellt ein Graph Mesh explizite, versionierte semantische Verknüpfungen zwischen Domänengraphen zum Zeitpunkt der Modellierung und Erfassung her – und nicht zum Zeitpunkt der Abfrage. Domänenübergreifende Beziehungen werden materialisiert, validiert und bidirektional indiziert, was Folgendes ermöglicht:
- Stabile und vorhersagbare Abfrageleistung
- Vollständige Graph-Traversal-Semantik über Systeme und Domänen hinweg
- Unternehmensweite Schlussfolgerungen über heterogene Quellen hinweg ohne zentralisierte Eigentumsverhältnisse
- Entkoppelte Weiterentwicklung von Domänenmodellen ohne Laufzeitabhängigkeitsketten
Aus Anwendersicht verhält sich ein Graph Mesh wie ein einziger großer Graph, während intern die Domänenautonomie und die semantische Dateneigentümerschaft erhalten bleiben.
Graph Mesh vs. Data Mesh
Data Mesh hat sich zu einem Organisations- und Architekturparadigma entwickelt, das sich darauf konzentriert, Daten als Produkt zu behandeln, mit dezentraler Eigentümerschaft und domänenorientierten Teams. Obwohl sie konzeptionell aufeinander abgestimmt sind, befassen sich Data Mesh und Graph Mesh mit unterschiedlichen Abstraktionsebenen.
Data Mesh konzentriert sich in erster Linie auf:
- Eigentumsverhältnisse und Verantwortlichkeiten für Datensätze
- Datenpipelines, Verträge und SLAs
- Analytische und operative Datennutzung
Graph Mesh erweitert diese Prinzipien auf die semantische Ebene:
- Explizite Darstellung von Entitäten und Beziehungen
- Gemeinsame Bedeutung über Domänen hinweg, nicht nur gemeinsame Daten
- Semantische Verträge anstelle von reinen Schema-Verträgen
In der Praxis ergänzt Graph Mesh Data Mesh:
- Datenprodukte legen Datensätze und Ereignisse offen
- Graph Mesh verbindet sie zu einem kohärenten semantischen Netzwerk
Ohne Graph Mesh besteht bei Data Mesh die Gefahr, dass semantische Silos in großem Maßstab reproduziert werden. Ohne die Prinzipien von Data Mesh besteht bei Graph Mesh die Gefahr zentraler Engpässe. Gemeinsam bilden sie eine nachhaltige Unternehmensdaten- und Wissensarchitektur.
AI-Agenten und Schema-Slicing im Linksphere Graph Mesh
Große Sprachmodelle und agentenbasierte AI-Systeme erhöhen den Bedarf an hochwertigem, semantisch fundiertem Unternehmenswissen. Rohdaten-Lakes oder Dokumentenkorpora reichen jedoch nicht aus, um die Anforderungen von Unternehmen an Vertrauenswürdigkeit, Präzision und Erklärbarkeit zu erfüllen.
Knowledge Graphen liefern die fehlende strukturelle Ebene:
- Eindeutige Entitätsidentität
- Typisierte Beziehungen
- Geschäftsorientierte Semantik
- Rückverfolgbarkeit und Herkunft
Innerhalb des Linksphere Graph Mesh dienen domänenbezogene Wissensgraphen als maßgebliche semantische Quellen für AI-Systeme. AI-Agenten interagieren nicht direkt mit dem gesamten Unternehmensgraphen, sondern nutzen präzise abgegrenzte semantische Ansichten, die daraus abgeleitet werden.
Schema Slicing als AI-Bereitstellungsmechanismus
Für AI-gesteuerte Anwendungsfälle, insbesondere Retrieval-Augmented Generation (RAG) und autonome Agenten, wird Schema Slicing zu einer entscheidenden Funktion. In Linksphere ist Schema Slicing ein expliziter Mechanismus, mit dem den AI-Agenten genau das semantische Schema bereitgestellt wird, das sie benötigen – nicht mehr und nicht weniger. Schema Slicing beschreibt die Fähigkeit, aus großen Unternehmensgraphen aufgabenspezifische, minimale semantische Ansichten abzuleiten:
- Es werden nur relevante Entitätstypen, Beziehungen und Einschränkungen offengelegt.
- Die Domänenhoheit und Zugriffskontrolle bleiben erhalten.
- Die kognitive und rechnerische Belastung für KI-Systeme wird reduziert.
In einem Graph Mesh können Schema-Slices domänenübergreifend zusammengestellt werden, ohne dass vollständige interne Modelle offengelegt werden müssen. Dadurch können AI-Systeme mit präzisen, kontrollierten semantischen Teilmengen arbeiten, anstatt mit unkontrollierten globalen Graphen. Schema Slicing stellt somit eine wichtige Brücke zwischen groß angelegten Knowledge-Graph-Architekturen und der praktischen KI-Implementierung dar.
Unser Fazit
Ein wesentlicher Vorteil des Graph-Mesh-Ansatzes ist die Souveränität:
- Die Datenhoheit verbleibt innerhalb der Domänen
- Autorisierungsmodelle bleiben lokal
- Die Ontologieentwicklung ist domänenorientiert
Gleichzeitig erhalten Unternehmen eine einheitliche semantische Karte ihrer Datenlandschaft. Durch die explizite Verknüpfung von Geschäftsobjekten über domänenübergreifende Wissensgraphen entsteht ein wirklich ganzheitlicher Enterprise Knowledge Graph – ohne dass ein zentral definierter Business-Graph erforderlich ist.
Jeder Domänen-Graph definiert und entwickelt seine eigenen Geschäftsobjekte und -beziehungen. Domänenübergreifende Verknüpfungen verbinden diese Objekte zu einer lebendigen, unternehmensweiten Wissensstruktur, die vollständig mit den Mesh-Prinzipien übereinstimmt.
Aus Business-Perspektive verändert diese Architektur grundlegend, wie Unternehmen Wissen skalieren können:
- Schnellere Amortisationszeit durch autonome Domänenteams und reduzierte domänenübergreifende Koordination
- Geringeres Betriebsrisiko durch Entkopplung des Verbrauchs von produktiven Quellsystemen
- Nachhaltige Governance ohne zentrale Engpässe oder semantische Fragmentierung
- Vorhersagbare Leistung für funktionsübergreifende und KI-gesteuerte Anwendungsfälle
- AI-fähige Semantik, die vertrauenswürdige, erklärbare und kontrollierte AI-Systeme ermöglicht
Anstatt zu versuchen, Wissen zu zentralisieren oder zum Zeitpunkt der Abfrage zu bündeln, ermöglicht Graph Mesh Unternehmen die Skalierung von Wissen auf organisatorischer, semantischer und operativer Ebene. Es passt die technische Architektur an die tatsächliche Arbeitsweise großer Organisationen an – verteilt, sich weiter entwickelnd und domänenorientiert.
Graph Mesh ist daher nicht nur ein Architekturmodell, sondern eine grundlegende Fähigkeit zum Aufbau resilienter, skalierbarer und KI-fähiger Unternehmen.
Download unseres englischsprachigen Whitepapers:
Graph Mesh and Domain Knowledge Graphs, A Holistic Enterprise Graph Approach, Darmstadt, 2026



