




Graph Mesh and Domain Knowledge Graphs
Two Decades of Knowledge Graph Engineering
Our experience with knowledge graphs dates back to the early 2000s. At that time, most knowledge graphs were modeled and maintained manually, were often limited in scope, and difficult to maintain. CONWEAVER is among the pioneers who automatically linked knowledge graphs from heterogeneous data sources and shifted the focus from manually created structures to machine-assisted graph construction. Since then, both the volume of data and the granularity of the models have increased significantly. Graphs have evolved from isolated datasets into enterprise-wide representations that encompass all areas of research and development (R&D), production, supply chains, and sales. This was made possible not only by advances in software and graph technology but also by a fundamental shift in the way knowledge graphs are modeled, managed, and further developed.
Two Fundamental Paradigms: Data-Driven vs. Business-Driven
There are two fundamental approaches to modeling knowledge graphs:
In a data-driven approach, the available data sources are analyzed first. The structure of the knowledge graph is derived from schemas, data patterns, and relationships found in operational systems.
- Strengths: High fidelity to real-world data, rapid onboarding of large datasets, high traceability, and data lineage.
- Limitations: Resulting graphs are often optimized for a single use case; there is limited reusability across domains; business semantics may remain implicit or fragmented.
In a business-driven approach, the knowledge graph is designed top-down. Business processes and domain concepts are captured in interviews and workshops and form a conceptual model to which the data is subsequently mapped.
- Strengths: Clear business semantics, alignment with processes and organizational language.
- Limitations: High initial modeling effort, risk of oversized models; in “greenfield” modeling, business requirements are often still unknown.
In practice, we have encountered numerous failed corporate initiatives in which large, model-driven graphs were designed without a sufficient foundation in real-world data. These projects often fail before the first production dataset is integrated.
The Necessary Hybrid of Data and Business Ontologies
Purely data-driven or purely model-driven approaches rarely scale well on their own. In reality, a hybrid approach is necessary. At CONWEAVER, we derive models from data and continuously align them with stakeholders.
This results in a two-tiered modeling approach:
- Data ontologies that represent source systems, schemas, and technical origins.
- Business ontologies that represent domain concepts, processes, and business meaning.
The data ontology ensures traceability back to the original systems, while the business ontology provides semantic context and cross-domain meaning.
Example: The business concept “Part”
A business concept such as “Part” can be linked to multiple data objects:
- SAP material master records
- Siemens Teamcenter TC_Item
- Demand or planning system entities
Depending on the phase of the product lifecycle, the business object maintains different relationships with these data objects. Over time, these links grow and enable derived relationships with suppliers, customers, and other business units.
The Challenges of Scaling: From Technology to Organization
As knowledge graphs grow in size and scope, new challenges arise that are rarely purely technical in nature. The primary bottleneck is organizational: central ontology teams become overburdened, modeling and governance efforts grow exponentially with the number of domains, and cross-domain coordination slows down innovation.
We consistently observe that teams deeply familiar with a specific domain require significantly more coordination to extend their model into new domains than newly formed domain teams that already possess the relevant expertise.
This insight fundamentally changes how knowledge graphs should be organized and managed.
Our Approach: Domain Knowledge Graphs and Graph Mesh
To address these challenges, we at CONWEAVER rely on the graph-mesh approach: Each domain owns and develops its own domain knowledge graph, teams work largely independently, and only the interfaces between domains are negotiated. These are defined as data contracts.
The loose coupling between domains enables teams to innovate locally while remaining interoperable at the enterprise level.
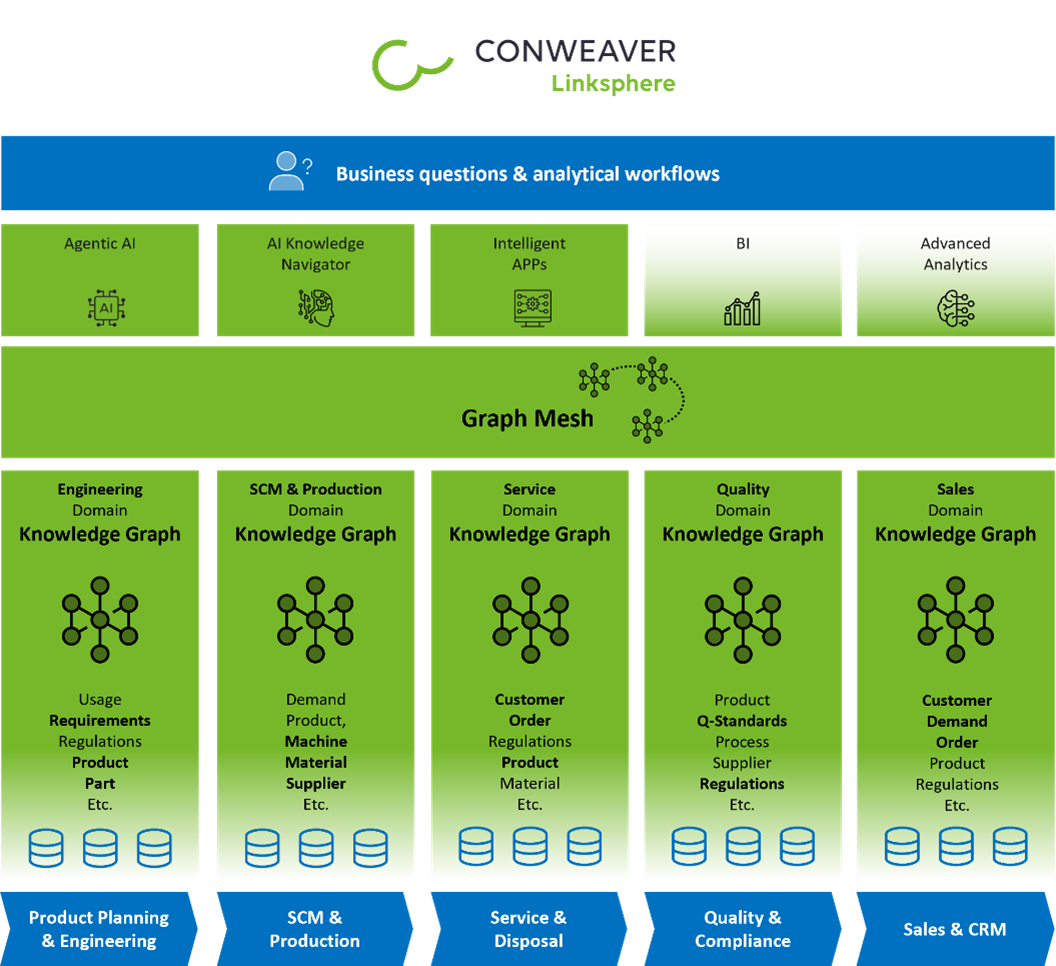
Bidirectional Indexing and Cross-Domain Performance
To support cross-domain use cases, loosely coupled domain endpoints within the Graph Mesh are connected via explicit, materialized cross-domain relationships. These relationships are indexed and bidirectional in their traversal semantics, allowing navigation from either side of a domain boundary.
This enables high-performance cross-domain traversal without relying on the execution of federated queries at runtime. Unlike traditional federated approaches for knowledge graphs, a Graph Mesh behaves like a single, coherent graph:
- No join queries at query time
- No runtime query barriers between domains
- Predictable cross-domain traversal performance
- Transparent, bidirectional navigation across domains
In the Linksphere Graph Mesh, cross-domain queries are executed and function as if they were operating on a single large graph, while domain models and ownership relationships remain decoupled.
Graph Mesh vs. Federated Knowledge Graphs
Many enterprise knowledge graph initiatives are based on federated query approaches. In these architectures, multiple graphs or data stores remain isolated, and cross-domain queries are resolved at query time by distributing subqueries and aggregating the results. While this approach may seem attractive from an integration perspective, it comes with structural limitations.
- Runtime coupling: Query execution depends on the availability and performance of all involved systems.
- Unpredictable performance: Latency accumulates across domains, making it difficult to operationalize cross-functional queries.
- Limited cross-domain inferences: Inference across system boundaries is limited or impossible at query time.
- Implicit dependency vulnerability: Changes to a domain’s data, semantics, or schemas can affect cross-domain queries, but these dependencies remain implicit and are only detected at runtime.
Beyond performance and availability, federated approaches face a more fundamental challenge - the explicit management of system boundaries and semantic links:
- Cross-system relationships must be calculated dynamically rather than explicitly modeled.
- Semantic discrepancies between systems (e.g., eBOM vs. mBOM structures) cannot be reliably resolved at query time.
- “Intelligent” cross-system links require domain knowledge that is not available during query execution.
- Broken or dangling references cannot be systematically detected or tracked - systems may refer to entities that no longer exist or were never semantically aligned.
As a result, federated models treat cross-domain connections as an execution problem rather than a modeling problem. In contrast, a graph mesh establishes explicit, versioned semantic links between domain graphs at the time of modeling and capture - not at the time of query. Cross-domain relationships are materialized, validated, and bidirectionally indexed, enabling the following:
- Stable and predictable query performance
- Complete graph traversal semantics across systems and domains
- Enterprise-wide inferences across heterogeneous sources without centralized ownership
- Decoupled evolution of domain models without runtime dependency chains
From the user’s perspective, a Graph Mesh behaves like a single large graph, while internally domain autonomy and semantic data ownership are preserved.
Graph Mesh vs. Data Mesh
Data Mesh has evolved into an organizational and architectural paradigm that focuses on treating data as a product, with decentralized ownership and domain-oriented teams. Although they are conceptually aligned, Data Mesh and Graph Mesh operate at different levels of abstraction.
Data Mesh primarily focuses on:
- Ownership and responsibilities for datasets
- Data pipelines, contracts, and SLAs
- Analytical and operational data usage
Graph Mesh extends these principles to the semantic level:
- Explicit representation of entities and relationships
- Shared meaning across domains, not just shared data
- Semantic contracts instead of pure schema contracts
In practice, Graph Mesh complements Data Mesh:
- Data products expose datasets and events
- Graph Mesh connects them into a coherent semantic network
Without Graph Mesh, Data Mesh runs the risk of reproducing semantic silos on a large scale. Without the principles of Data Mesh, Graph Mesh runs the risk of central bottlenecks. Together, they form a sustainable enterprise data and knowledge architecture.
AI Agents and Schema Slicing in the Linksphere Graph Mesh
Large language models and Agentic AI are increasing the demand for high-quality, semantically grounded enterprise knowledge. However, raw data lakes or document corpora are insufficient to meet enterprises’ requirements for trustworthiness, precision, and explainability.
Knowledge graphs provide the missing structural layer:
- Unique entity identity
- Typed relationships
- Business-oriented semantics
- Traceability and provenance
Within the Linksphere Graph Mesh, domain-specific knowledge graphs serve as authoritative semantic sources for AI systems. AI agents do not interact directly with the entire enterprise graph, but rather use precisely delimited semantic views derived from it.
Schema Slicing as an AI Deployment Mechanism
For AI-driven use cases, particularly Retrieval-Augmented Generation (RAG) and autonomous agents, schema slicing is becoming a critical feature. In Linksphere, schema slicing is an explicit mechanism that provides AI agents with exactly the semantic schema they need - no more and no less. Schema Slicing describes the ability to derive task-specific, minimal semantic views from large enterprise graphs:
- Only relevant entity types, relationships, and constraints are exposed.
- Domain sovereignty and access control are preserved.
- The cognitive and computational load on AI systems is reduced.
In a graph mesh, schema slices can be assembled across domains without having to disclose complete internal models. This allows AI systems to work with precise, controlled semantic subsets rather than uncontrolled global graphs. Schema slicing thus represents an important bridge between large-scale knowledge graph architectures and practical AI implementation.
Our Conclusion
A key advantage of the graph-mesh approach is sovereignty:
- Data sovereignty remains within the domains
- Authorization models remain local
- Ontology development is domain-oriented
At the same time, companies gain a unified semantic map of their data landscape. By explicitly linking business objects via cross-domain knowledge graphs, a truly holistic enterprise knowledge graph emerges - without the need for a centrally defined business graph.
Each domain graph defines and develops its own business objects and relationships. Cross-domain links connect these objects into a living, enterprise-wide knowledge structure that is fully aligned with the Mesh principles.
From a business perspective, this architecture fundamentally changes how companies can scale knowledge:
- Faster time to value through autonomous domain teams and reduced cross-domain coordination
- Lower operational risk by decoupling consumption from production source systems
- Sustainable governance without central bottlenecks or semantic fragmentation
- Predictable performance for cross-functional and AI-driven use cases
- AI-enabled semantics that enable trustworthy, explainable, and controlled AI systems
Instead of attempting to centralize knowledge or aggregate it at query time, Graph Mesh enables companies to scale knowledge at the organizational, semantic, and operational levels. It adapts the technical architecture to the actual way large organizations operate - distributed, evolving, and domain-oriented.
Graph Mesh is therefore not just an architectural model, but a fundamental capability for building resilient, scalable, and AI-enabled enterprises.
Download our whitepaper:
Graph Mesh and Domain Knowledge Graphs, A Holistic Enterprise Graph Approach, Darmstadt, 2026



